Given a sequence of strings, the task is to find out the second most repeated (or frequent) word or string in a sequence. (Considering no two words are the second most repeated, there will be always a single word).
Table of Contents
Example
Input:
{“aaa”, ”bb”, ”bb”, ”aaa”, ”aaa”, c”}
Output:
String with second highest frequency is: bb
Main idea
We will store the frequency of each string in a hash table and after that, we can just iterate the hash table to find the string with the second-highest frequency.
What is a hash table?
The Hash table is a data structure that stores data in an associative manner. In hash tables, keys are mapped to its values, where each key has a unique index. So if we know the index of the desired value, then it becomes very fast and efficient to access it. Hash table uses hashing to calculate a unique index for each key, also called hash code, by which the desired value can be found.
A basic hash table consists of two parts:
- Hash function
A hash function is used to do hashing which determines the index of our key-value pair. Choosing an efficient hash function is a crucial part of creating a good hash table. We should always ensure that it’s a one-way function, i.e., the key cannot be retrieved from the hash. Another thing which should be considered is that the hash function does not produce the same hash code for different keys. - Array
The array holds all the key-value entries in the table. The size of the array should be set according to the amount of data expected.
Algorithm for Second Most Repeated Word in a Sequence
- Declare a hash table.
- Store the frequency of each string in a hash table.
- Iterate over the hash table and find the string with the second-highest frequency.
- Print the string.
Understand with Example
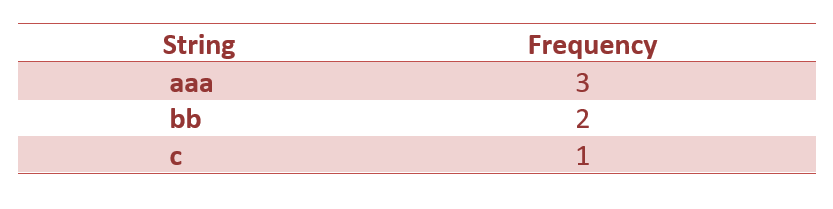
Input: {“aaa”, ”bb”, ”bb”, ”aaa”, ”aaa”, c”}
The hash table will look like this:
Implementation
C++ program for Second Most Repeated Word in a Sequence
#include <bits/stdc++.h>
using namespace std;
string stringWithSecondHighestFrequency(vector<string> &A)
{
unordered_map<string, int> hash_table;
// Store the frequency of strings in a hash table
for (int i = 0; i < A.size(); i++)
{
hash_table[A[i]]++;
}
// Find the second highest frequency
int max_freq = 0;
int second_highest_freq = 0;
for (auto ele : hash_table)
{
max_freq = max(max_freq, ele.second);
if (second_highest_freq < ele.second && ele.second < max_freq)
{
second_highest_freq = ele.second;
}
}
// Find the string with second_highest_freq
for (auto ele : hash_table)
{
if (ele.second == second_highest_freq)
{
return ele.first;
}
}
}
int main()
{
vector<string> A = {"aaa", "bb", "bb", "aaa", "aaa", "c"};
cout << "String with second highest frequency is: " << stringWithSecondHighestFrequency(A) << endl;
return 0;
}
String with second highest frequency is: bb
JAVA program for Second Most Repeated Word in a Sequence
import java.util.*;
public class Main
{
public static String stringWithSecondHighestFrequency(String[] A)
{
int n = A.length;
HashMap<String,Integer> hash_table = new HashMap<String,Integer>();
// Store the frequency of strings in a hash table
for (int i = 0; i < n; i++)
{
Integer j = hash_table.get(A[i]);
hash_table.put(A[i], (j == null) ? 1 : j + 1);
}
// Find the second highest frequency
int max_freq = 0;
int second_highest_freq = 0;
for (Map.Entry<String,Integer> entry : hash_table.entrySet())
{
max_freq = Math.max(max_freq, entry.getValue());
if (second_highest_freq < entry.getValue() && entry.getValue() < max_freq)
{
second_highest_freq = entry.getValue();
}
}
// Find the string with second_highest_freq
for (Map.Entry<String,Integer> entry : hash_table.entrySet())
{
if (entry.getValue() == second_highest_freq)
{
return entry.getKey();
}
}
return "";
}
public static void main(String[] args) {
String[] A = {"aaa", "bb", "bb", "aaa", "aaa", "c"};
System.out.println("String with second highest frequency is: "+stringWithSecondHighestFrequency(A));
}
}
String with second highest frequency is: bb
Complexity Analysis for Second Most Repeated Word in a Sequence
Time complexity
We are iterating the vector-only once, so the time complexity is O(N).
Space complexity
We are maintaining a hash table, so the space complexity is O(N).