Table of Contents
Problem Statement
In this problem we are given an array of integers and we have to check if there exists any duplicate element which are at a distance of at least k to each other.
i.e. the difference between the indices of those two same element should be less than equal to k.
Or, nums[i]==nums[j] and abs(i-j)<=k
Example
nums = [1,2,3,1], k = 3
true
Explanation:
element at index 0 and 3 is same, and 3 – 0 <= k.
nums = [1,2,3,1,2,3], k = 2
false
Approach 1 (Brute Force)
If we talk about brute force approach, we can simply implement the program using two loops and check for each element of the array to a distance k right from it whether there is any element present or not.
If any element is found same to the current element then we return true otherwise we return false.
Algorithm
- Run a loop for every element nums[i] of the given array.
- Inside this loop again run a for loop and traverse all the elements from j=i+1 to j=i+k and compare its value to the nums[i].
- If nums[j]==nums[i] then return true. As we have found an element.
- Finally when no duplicate element is found then return false before exiting the function.
Implementation for Contains Duplicate II Leetcode Solution
C++ Program
#include <bits/stdc++.h>
using namespace std;
bool containsNearbyDuplicate(vector<int>& nums, int k)
{
for(int i=0;i<nums.size();i++)
for(int j=i+1;j<nums.size() && j<=i+k;j++)
{
if(nums[j]==nums[i])
return true;
}
return false;
}
int main()
{
vector<int> nums={1,2,3,1};
int k=3;
if(containsNearbyDuplicate(nums, k))
cout<<"true"<<endl;
else
cout<<"false"<<endl;
return 0;
}
true
Java Program
class Rextester{
public static boolean containsNearbyDuplicate(int[] nums, int k)
{
for(int i=0;i<nums.length;i++)
for(int j=i+1;j<nums.length && j<=i+k;j++)
{
if(nums[j]==nums[i])
return true;
}
return false;
}
public static void main(String args[])
{
int[] nums={1,2,3,1};
int k=3;
System.out.println(containsNearbyDuplicate(nums,k) );
}
}
true
Complexity Analysis for Contains Duplicate II Leetcode Solution
Time Complexity
O(n*min(k,n)) : We are traversing min(k,n) elements for every element of the array. Hence time complexity will be O(n*min(k,n)).
Space Complexity
O(1) : Constant space.
Approach 2 (Sliding Window)
As we can see we are going more than one time to the elements of the array which increases its time complexity. We should visit only once to each element for reducing the time to O(n).
For that what we can do is we can keep a sliding window of previous k elements using a Hash Set each time we are visiting any element of the array. By doing this we can easily check from the set of previous k elements if there exist an element in the set which is same as the current element that we are visiting. If we found one in set, then at that moment we return true. Else we will insert the current element in the set and also remove the last visited element from the set so that we always have k previous elements in our set.
Lets see an example in figure below:
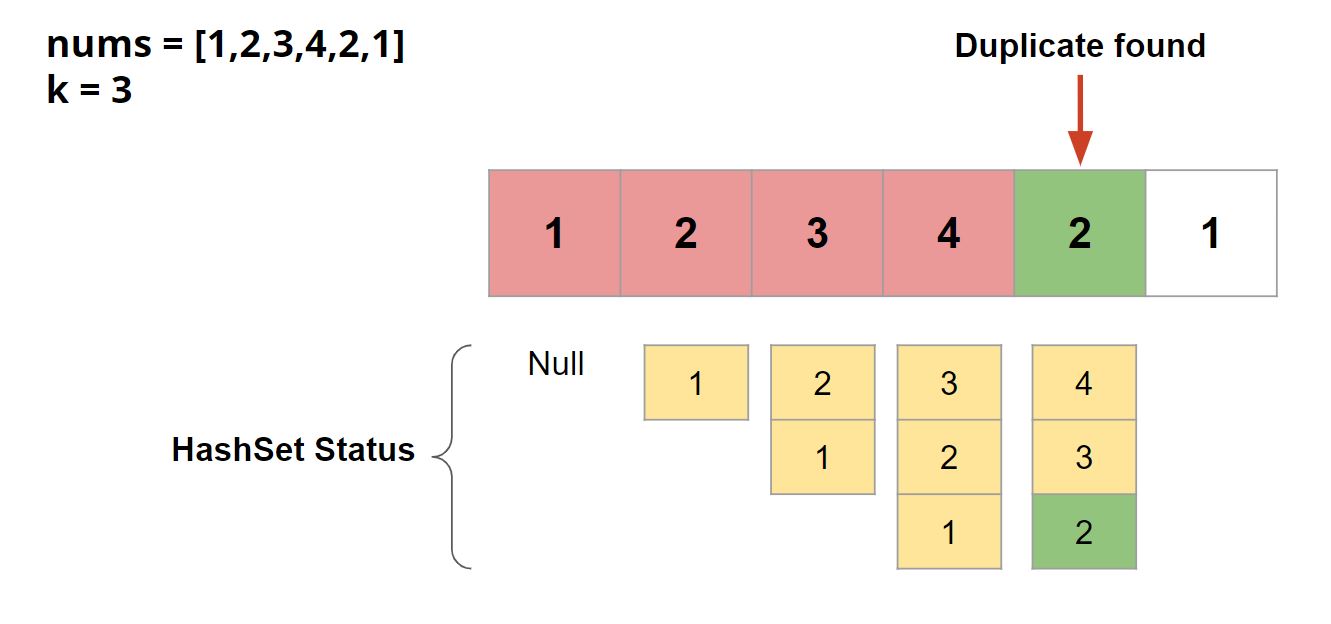
Algorithm
- Create a Hash Set for storing k previous elements.
- Traverse for every element nums[i] of the given array in a loop.
- Check if hash set already contains nums[i] or not. If nums[i] is present in the set ( i.e. duplicate element is present at distance less than equal to k ), then return true. Else add nums[i] to the set.
- If size of the set becomes greater than k then remove the last visited element (nums[i-k]) from the set.
- Finally when no duplicate element is found then return false before exiting the function.
Implementation for Contains Duplicate II Leetcode Solution
C++ Program
#include <bits/stdc++.h>
using namespace std;
bool containsNearbyDuplicate(vector<int>& nums, int k)
{
unordered_set<int> set;
for(int i=0;i<nums.size();i++)
{
if(set.count(nums[i])) return true;
set.insert(nums[i]);
if(set.size()>k)
set.erase(nums[i-k]);
}
return false;
}
int main()
{
vector<int> nums={1,2,3,1};
int k=3;
if(containsNearbyDuplicate(nums, k))
cout<<"true"<<endl;
else
cout<<"false"<<endl;
return 0;
}
true
Java Program
#include <bits/stdc++.h>
using namespace std;
bool containsNearbyDuplicate(vector<int>& nums, int k)
{
unordered_set<int> set;
for(int i=0;i<nums.size();i++)
{
if(set.count(nums[i])) return true;
set.insert(nums[i]);
if(set.size()>k)
set.erase(nums[i-k]);
}
return false;
}
int main()
{
vector<int> nums={1,2,3,1};
int k=3;
if(containsNearbyDuplicate(nums, k))
cout<<"true"<<endl;
else
cout<<"false"<<endl;
return 0;
}
true
Complexity Analysis for Contains Duplicate II Leetcode Solution
Time Complexity
O(n) : As we visit each element only once and assuming that adding an element and removing an element takes constant time in hash set time complexity reduced to just O(n).
Space Complexity
O(min(k,n)) : We are storing k elements at max in the hash set. If k>n then only n element will be stored in the set at max.