The Internet is a huge resource of data for any field of research or personal interest. Python Web Scraping using Beautiful Soup is used to collect the data from the internet. The Python libraries’ requests and Beautiful Soup are powerful tools used for web scraping. If you know the basics of Python and HTML, then you can go ahead with this tutorial. We can solve some hands-on examples in this tutorial which will help you to learn more about web scraping.
Table of Contents
What you will learn from this tutorial?
- How to scrape and parse data from the web using python libraries requests and Beautiful Soup.
- An idea about the web scraping pipeline end to end.
- As a hands-on example, we are going to write a code in Python to retrieve job offers from the webpage and print only relevant information in the console.
Using the same technique and the same tools you can get data from any static website available on the world wide web.
Why we need web scraping?
The Internet is a huge resource of data for any field of research or for your personal interest. We need web scraping to collect the data from the internet to make our job easier. Web scraping is useful especially when you need to extract large amounts of data from the internet. The extracted data can be saved either on your local computer or to a database.
Some websites will not allow us to save a copy of the data displayed on the web browser for personal use. In that case, we have to manually copy and paste the data – a difficult job that can take hours to complete if you have large data to copy. Instead of doing the work manually, we are going to automate this process with web scraping.
The powerful tools used for web scraping are the Python libraries requests and Beautiful Soup. In this tutorial, we will learn about Python Web Scraping using Beautiful Soup.
Python Web Scraping using Beautiful Soup
Web scraping is useful when you need to extract large amounts of data from the internet. The extracted data can be saved either on your local computer or to a database.
Some websites will not allow us to save a copy of the data displayed on the web browser for personal use. In that case, we have to manually copy and paste the data – a difficult job that can take hours to complete if you have large data to copy. Instead of copying the data manually from websites, we can automate this process with the help of web scraping. The web scraping software will perform the same manual task for us with less time.
However, some websites won’t allow the automated scrapers to scrape their data while others don’t care. Before you scrape data from the website make sure you don’t violate any Terms of Service. Please check out Legal Perspectives on Scraping Data From The Modern Web which explains more about the legal aspects of web scraping,
Why there is a need to scrape the data?
Let’s say if you are looking for a specific product on Amazon. You just don’t want to buy at any cost. You want to buy when there is a certain discount in price. Amazon announces offers on that product now and then. You keep checking it every day but that’s not the productive way to spend your time.
When you need to extract large data from websites that are frequently updated with new content you end up spending a lot of time searching, scrolling, and clicking. Manual web scraping is repetitive work and you end up spending a lot of time on that.
Here Python comes to your rescue. Instead of checking the price of the product every day, you can write a Python script to automate this repetitive process. To speed up the data collection process the solution is Automated web scraping. You are going to write your Python script only once nad the script will fetch you the information you need as many as times and from as many pages you want.
In the world of the internet, a lot of new content is uploaded every second. You can collect those data, whether it’s for job search for personal use, automated web scraping will help you to achieve your goal.
What are the challenges?
Each website is different because there are a lot of new technologies that arise every day and the website continues to grow. This poses challenges you will face when you try to scrape a website.
Variety
Each website is unique. So you cannot write a single script and expect it to for all the websites. You need to work on how to extract the relevant information from a website.
Durability
You have a script that fetches the relevant information for you from a website. But the website is not going to remain constant. The website changes now and then according to the trend. After the website has changed, your script might not work properly and throws a lot of errors.
This is a real-time scenario because thanks to the agile most of the websites are in active development these days. Once the website has changed, your script might not fetch you the expected result. But can you update your script will minimal changes because most of the changes to the websites are small and incremental, which is a good thing.
Considering all these, your script needs continuous maintenance. By building a continuous integration, you can make sure your script works properly and doesn’t break without your knowledge.
Python Web Scraping API
API is the substitute for web scraping. The abbreviation for API is the Alternative Programming Interface. Some website providers offer API to access their data in a predefined manner. With APIs, you can access the data directly using XML and JSON without parsing HTML.
HTML defines the structure of web content. When the HTML of the website changes, the API remains stable, unlike the automated scraping script. So APIs are efficient than web scraping in collecting data from the internet.
However, the challenges of web scraping apply to APIs as well. Also, it’s difficult to inspect the structure of the API if the documentation provided lacks in quality.
APIs are not a part of this tutorial. Let’s proceed with web scraping.
Scraping the Job site (Python Web Scraping Demo)
In this tutorial, we are going to scrape the Monster job site to fetch the job listings of a software developer. The Web scraper we are going to develop will parse the HTML content and get the relevant information by filtering the content for specific words.
You can scrape any website but the difficulty of doing it differs from website to website. In this tutorial, you will understand the overall process. You can scrape the other websites from that knowledge.
Part 1: Examine the data source
We can start scraping by opening the website that you want to scrape, in your favorite browser. To extract the information, you will need to understand the structure of the job site.
Explore the website
Go the monster website and search for the software developer jobs in Dublin using the monster website’s native search.
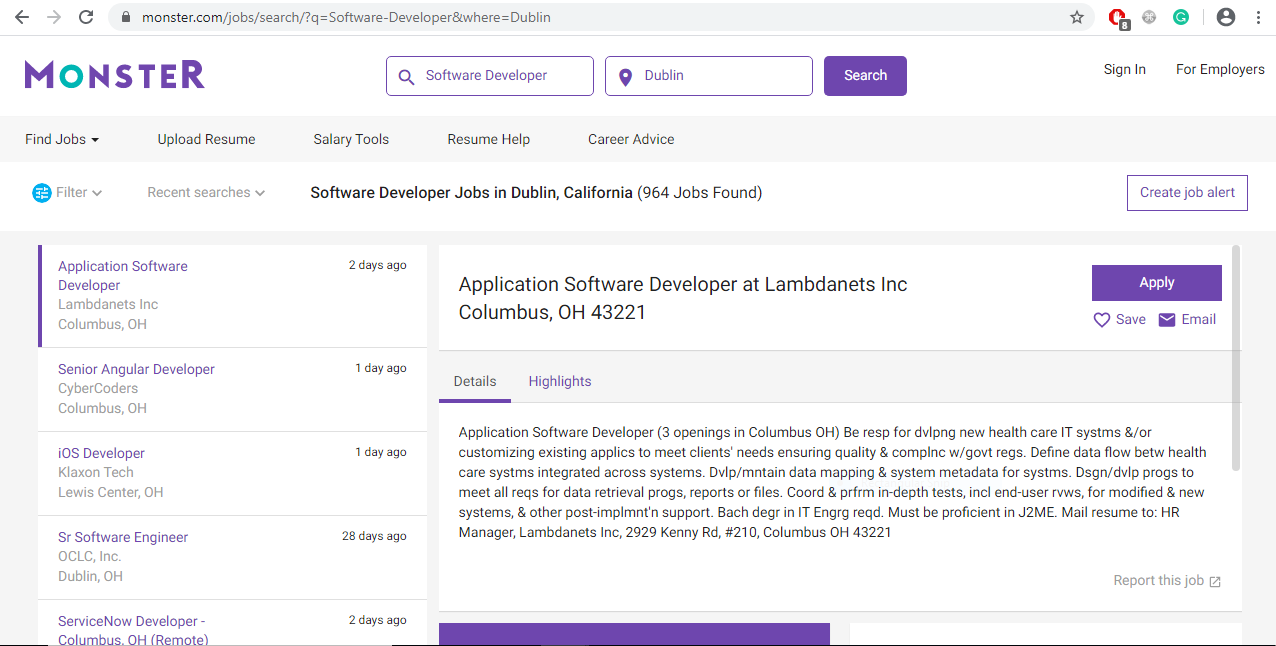
The search returned a lot of job listings. You can see a list of jobs on the left side. When you click a particular job, you can see a more detailed description of that job on the right side. Also when you click a specific job notice that URL in your browser’s address bar also changes.
Understand the encoded information in the URL
The URL contains a lot of encoded information. It will be much easier for you to work with the web scraping if you become familiar with how the URLs works and what information it contains. This is the URL of the website we are using for this tutorial:
https://www.monster.com/jobs/search/?q=Software-Developer&where=Dublin
We can split the URL into two main parts:
Base URL
The path to the search functionality of the website represents the base URL. The base URL in our example is “https://www.monster.com/jobs/search/”
Query parameters
The additional values declared on the website represents the query parameters. The query parameters in our example are “?q=Software-Developer&where=Dublin”. We can also say that everything present after ‘?’ in the URL is the query parameters.
You can notice that the base URL remains the same. The query parameters changes based on the search criteria. The usage of query parameters is similar to how query strings used in the database to fetch the specific records.
The query parameter is generally made up of these 3 things:
Start
The question mark ‘?’ indicates the start of the query parameter.
Information
The query parameter contains information encoded in key-value pairs. The equal sign joins together the respective key and values (key=value).
Separator
The URL can contain multiple query parameters. The ampersand(&) symbol separates each query parameter.
Examine our URL based on the above information. Our URL has two key-value pairs:
- q=Software-Developer, which defines the type of job we are searching for.
- where=Dublin, which represents the location we are looking for.
If you change the search criteria, the query parameters will be changed accordingly. Lets test that by changing the search criteria like below:

The URL will be :
https://www.monster.com/jobs/search/?q=Software-Developer&where=India
You can also change the query parameters in the URL, the search criteria will be changed accordingly. Change the URL and check the search bar.
https://www.monster.com/jobs/search/?q=Software-Developer&where=Australia
The search results can be modified either by changing the data in the search bar or query parameters in the URL. By understanding the information present in the URL, you can retrieve data from the website.
Inspect the website
You need to understand the structure of a webpage, to retrieve the data you want. HTML is responsible for how the webpage is structured for display. You will get the HMTL response of a webpage using Developer Tools.
All modern web browsers include a suite of developer tools that are powerful as well. With these tools do a lot of things, from inspecting currently-loaded HTML, CSS, and JavaScript to showing which assets the page has requested and how long they took to load.
In this tutorial, we will see how to work with the Chrome browser’s developer tools. In the Chrome browser, there are 2 ways to open developer tools.
- One option is in the menu bar, View->Developer->Developer tools.
- Another option is to right-click on the webpage and select Inspect.
You can interact with the webpage’s DOM through developer tools. The DOM is a cross-platform and language-independent interface that allows programs and scripts to dynamically access and update the content, structure, and style of a document. By selecting the Elements tab in developer tools you can start digging into the webpage’s DOM. You can edit, expand, and collapse the elements in the browser.
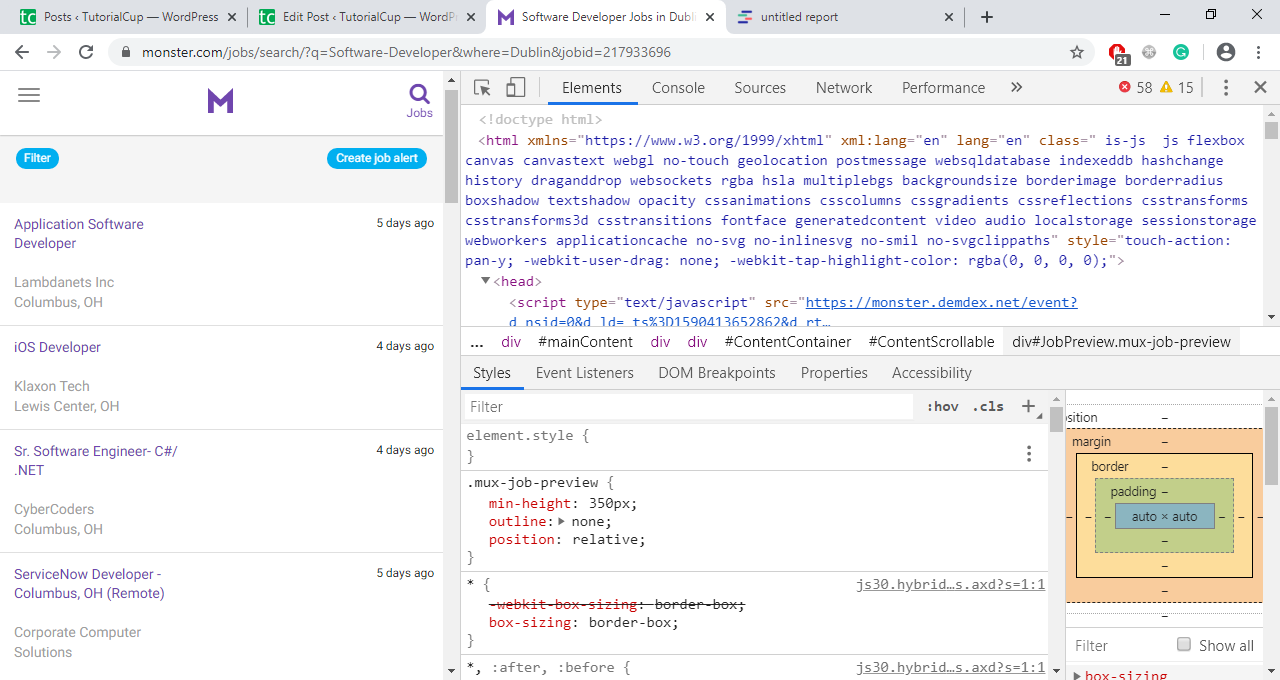
What you are seeing is nothing but the HTML structure of the web page. If you want to inspect a particular job, right-click on the job and select inspect. You will be taken to where the element is located in the DOM. You can hover over the HTML content and corresponding changes will be highlighted on the webpage.
If you understand the structure of the webpage in a better way, it will be easier for you to scrape the data. If you are worried about this, don’t worry we will be extracting only the interesting parts with Beautiful Soup.
Part 2: Scraping the webpage for HTML content
Since you have a basic idea about what we were working with, let’s get into the python part. As a first step, we need to get the website’s HTML code into our Python script. For this task, we need Python’s requests library. Let’s install requests by typing the below command in your terminal.
pip install requests
Go to your text editor and open a new python file. Below is the code to get the HTML code of a webpage using Python.
import requests URL='https://www.monster.com/jobs/search/?q=Software-Developer&where=Dublin' page=requests.get(URL)
The URL of the webpage we are going to scrape is assigned to the URL variable. In the above code, we are doing is making an HTTP request to the URL. We are getting a response back from a server and saving it into a variable called a page. You can see the HTML data we received, by printing the content attribute.
print(page.content)
The output is nothing but the HTML content we have seen in the elements tab of the developer tools. If you want to improve the structure of how the HTML code is displayed in the console, then use pprint instead of print. If you want to learn more about pprint then check out the official Python documentation.
import requests import pprint URL='https://www.monster.com/jobs/search/?q=Software-Developer&where=Dublin' page=requests.get(URL) pp = pprint.PrettyPrinter() pp.pprint(page.content)
Static Websites
We are scraping a static webpage for this tutorial. The server sends back all the HTML content, a user can see.
Below is the HTML code of one particular job posting. The code looks long and confusing.
<section class="card-content is-active" data-jobid="217939354" data-postingid="318203fa-aeaf-4573-b083-229633ddc854" onclick="MKImpressionTrackingMouseDownHijack(this, event)">
<div class="flex-row">
<div class="mux-company-logo thumbnail"></div>
<div class="summary">
<header class="card-header">
<h2 class="title">
<a
data-bypass="true"
href="https://job-openings.monster.com/ios-developer-lewis-center-oh-us-klaxon-tech/217939354"
onclick='clickJobTitle('plid=561&pcid=660&poccid=11970','Software Developer',''); clickJobTitleSiteCat('{"events.event48":"true","eVar25":"iOS Developer","eVar66":"Monster","eVar67":"JSR2CW","eVar26":"xklaxontechx_Klaxon Tech","eVar31":"Lewis Center_OH_","prop22":"Employee","prop24":"2020-05-21T12:00","eVar53":"1500127001001","eVar50":"Duration","eVar74":"regular"}')'
coretrack='{"olduuid":"8343b2e6-631a-4fb2-a6ec-1ff6397d5516","s_t":"t","j_jobid":"217939354","j_postingid":"318203fa-aeaf-4573-b083-229633ddc854","j_jawsid":"433081025","j_pvc":"monster","j_coc":"xklaxontechx","j_cid":"660","j_occid":"11970","j_lid":"561","j_p":"2","j_lat":"40.1839","j_long":"-82.9843","j_jpt":"1","j_jpm":"1","j_placementid":"JSR2CW","s_search_query":"q%3DSoftware%2520Developer%26brd%3D1%26brd%3D2%26cy%3DUS%26pp%3D25%26sort%3Drv.di.dt%26nosal%3Dtrue%26geo%3DDublin%252c32.18688%252c1277021%252c580642%252c702%252cCity%26stp%3DScoreFenceHash","s_q":"Software%20Developer","s_where":"Dublin","j_pg":"1","a_affiliate_id":"Monster","uinfo":"-1","isloggedin":"False","uuid":"d9509d9a-f023-4273-9792-9666fce07cd3"}'
coretrackclickadded="true"
>
iOS Developer
</a>
</h2>
</header>
<div class="company">
<span class="name">Klaxon Tech</span>
<ul class="list-inline"></ul>
</div>
<div class="location">
<span class="name">
Lewis Center, OH
</span>
</div>
</div>
<div class="meta flex-col">
<time datetime="2017-05-26T12:00">4 days ago</time>
<span data-mux="tooltip" title="" class="mux-tooltip applied-only" mux1590415016860="13" data-original-title="Applied">
<i class="icon icon-applied" aria-hidden="true"></i>
<span class="sr-only">Applied</span>
</span>
<span data-mux="tooltip" title="" class="mux-tooltip saved-only" mux1590415016860="14" data-original-title="Saved">
<i class="icon icon-saved" aria-hidden="true"></i>
<span class="sr-only">Saved</span>
</span>
</div>
</div>
</section>
It is very difficult to look at such a long code. Use HTML formatter which formats the code and makes it easier to read. It will be much better to understand the structure of the code if the readability of the code is good. Remember that each website is different. So you have to inspect the webpage and understand the code structure.
The above HTML contains many different elements. For example, you can see a large number of <a> element. We are going to concentrate only on the “class” attribute.
class = “title”: title of the job posting
class=” company”: name of the company that offers the job posting
class=” location”: the location where you will be offered the job
We have learned how to get the HTML data using Python script from a static website. Before moving on to the beautiful soup to retrieve only the relevant information from the HTML, let’s take a look at other challenging situations.
Hidden Websites
Some webpages contain a hidden logic that you cannot see unless you log in to the page. For those webpages we need an account to scrap the data. The Python script to make HTTP requests to the hidden websites is different from the static websites. You may think you can login to the website, then scrape the data using Python just like we do static websites, but that’s not the case.
With requests, you need to use some advanced techniques to scrape the content behind the login. With these techniques, you can log in to the websites while making an HTTP request using the Python script.
Dynamic Websites
Static websites are easier to work with compared to dynamic websites because when working with static websites the server sends all the HTML code as a response. Then we can use beautiful soup to retrieve only the relevant information.
That’s not the case with dynamic websites. Because the server won’t send the HTML code at all, instead it sends a Javascript code as a response. This Javascript code looks entirely different from what we have inspected using the developer tools.
Many modern websites avoid crunching numbers on their servers in order to reduce the work from the server to client machines. They send a Javascript code instead, that the browser will execute the Javascript code locally to generate the HTML code.
Whatever happens in the background of the browser is not related to what happens in the script. From the Javascript code received from a server, the browser creates the DOM and HTML. But our Python script which is going to make an HTTP request to the dynamic website returns the Javascript code, not the HTML code.
The Javascript code which we received using requests library won’t be parsed by beautiful soup. We have to produce HMTL content from the Javascript code just like the way the browser does. Unfortunately, we can’t do that with the requests library but there are other options.
The author the requests library created a project called ‘requests-html’ which renders Javascript using the syntax similar to the syntax in requests. It also includes underlying implementation to parse the data using beautiful soup.
Selenium is another popular choice to scrape dynamic websites. Selenium acts as a slimmed-down browser that executes the Javascript code and passes the rendered HTML code for us.
In this tutorial, we are not going to cover how to scrape dynamic websites. However, just remember these points when you scrape a dynamic website.
Part 3: Parse the HTML code using Beautiful Soup
Now we have to how the get the HTML content from a webpage using the Python script. But the HTML code we received looks long and messy. There are lots of HTML elements and there is a mix of Javascript as well. Now we are going to parse this messy HTML code using Beautiful soup and retrieve only the relevant information.
To Parse the structured data Python provides a library called Beautiful Soup. With beautiful soup, you can interact with HTML in the same way as you interact with the webpage using developer tools. Beautiful soup provides a couple of functions that you can use to parse the HTML data.
Before we get started, install beautiful soup by entering the below command in the terminal.
pip install beautifulsoup4
Now import the beautiful soup library in your python script and create an object for it.
import requests from bs4 import BeautifulSoup URL='https://www.monster.com/jobs/search/?q=Software-Developer&where=Dublin' page=requests.get(URL) soup=BeautifulSoup(page.content,'html.parser')
In the above code, we are importing beautiful soup and creating an object for it. While creating the object we are passing the HTML data we received as a response from the webpage and appropriate parser as the input.
Find elements by id
In the HTML data, every element is assigned an id attribute. As the name indicates each element is uniquely identified by the id attribute. Let’s look into how to parse the webpage by selecting a particular item by its id.
Open your browser and go to developer tools. There is an HTML object that contains all the job postings, find that. Its always good practice to switch over to the browser periodically to interact with the webpage using developer tools. You can hover over the parts of the web page and inspect to find the exact elements you are looking for.
We are looking for <div> element with an id attribute containing the value “ResultsContainer”. Apart from the id attribute, the <div> element has other attributes as well. Below is the essence of the data we are looking for.
<div id="ResultsContainer">
<!-- all the job listings -->
</div>We can get element using its id in Python by adding the below line to your existing script:
results = soup.find(id='ResultsContainer')
To print it in a better format, you can use .prettify() on any beautiful soup object. Call the .prettify() method on the results variable and observe the output.
print(results.prettify())
Similar to the above method, we can extract any specific element from the HTML using its id. With this we can work with a particular part of HTML using the above method still, the HTML code is long and messy.
Find elements by Class Name
There is an element called <section> with class card-content, that wraps each job posting. Let’s filter the results variable to get only the job postings. This is the data, we are actually looking for. The code is simply one line:
jobs=results.find_all('section',class_='card-content')The .find_all() method on a beautiful soup object returns the iterable. With for loop, we can print each job element.
for job in jobs:
print(job, end='\n'*2)We have included two lines of space between each job element to differentiate each job element. It looks pretty neat now still, we can refine further by retrieving only title, company, and location.
<h2 class="title"><a data-bypass="true" data-m_impr_a_placement_id="JSR2CW" data-m_impr_j_cid="660" data-m_impr_j_coc="" data-m_impr_j_jawsid="417704839" data-m_impr_j_jobid="0" data-m_impr_j_jpm="1" data-m_impr_j_jpt="2" data-m_impr_j_lat="40.0994" data-m_impr_j_lid="561" data-m_impr_j_long="-83.0166" data-m_impr_j_occid="11970" data-m_impr_j_p="26" data-m_impr_j_postingid="95973ee2-e649-472c-8493-98a2bb9c6cd5" data-m_impr_j_pvc="diceftpin" data-m_impr_s_t="t" data-m_impr_uuid="9176e69f-0346-45a5-b85e-7cd8f6b93597" href="https://job-openings.monster.com/application-developer-columbus-oh-us-atash-enterprises-llc/95973ee2-e649-472c-8493-98a2bb9c6cd5" onclick="clickJobTitle('plid=561&pcid=660&poccid=11970','Software Developer','');clickJobTitleSiteCat('{"events.event48":"true","eVar25":"Application Developer","eVar66":"Monster","eVar67":"JSR2CW","eVar26":"_Atash Enterprises, LLC","eVar31":"Columbus_OH_","prop24":"2020-05-26T
12:00","eVar53":"1500127001001","eVar50":"PPC","eVar74":"reg
ular"}')">Application Developer
</a></h2>
<div class="company">
<span class="name">Atash Enterprises, LLC</span>
<ul class="list-inline">
</ul>
</div>
<div class="location">
<span class="name">
Columbus, OH
</span>
</div>This is how a single job element looks like. Still, there are a lot of HTML tags and attributes, we will narrow this further in the next step.
Filter the text content from HTML elements
By removing the text, you can see only the title, location, and company of each job posting. We can extract only the text content of the HTML elements by adding .text to a beautiful soup object.
for job in jobs:
title=job.find('h2',class_='title')
company=job.find('div',class_='company')
location=job.find('div',class_='location')
print(title.text)
print(company.text)
print(location.text)
print()Now in the output, you can see the text content, but there is a lot of whitespaces as well. Use .strip() to eliminate the whitespace. You can also use other Python string methods to clean up.
You will get an attribute error when you run the above code.
AttributeError: 'NoneType' object has no attribute 'text'
We cannot rely on a webpage to be consistent. When parsing HTML, there are more chances that we will get an error.
The previous code throws an error because it countered an item with None value. We cannot expect the webpage structure to be uniform. Some jobs might be advertised differently than others, so they return different results. We have to handle this in our program while parsing the HTML.
for job in jobs:
title=job.find('h2',class_='title')
company=job.find('div',class_='company')
location=job.find('div',class_='location')
if None in (title, company, location):
continue
print(title.text.strip())
print(company.text.strip())
print(location.text.strip())
print()We are including a conditional statement to eliminate the job elements which contain None for any of the title, company, or location. If you are interested you can find out why one of the elements has returned None.
After making these changes, check the output. It looks much better now:
Base24 Application developer - FULL TIME & Contract (C2C) Cystems Logic Columbus, OH Application Developer Atash Enterprises, LLC Columbus, OH
Find Elements by Class Name and Text Content
We have collected the list of Software Developer Jobs, the company which offers those positions and location of the job. If you are looking only for a Python Developer position, then we can make changes in the script and make it more useful. We can filter only the Python Developer jobs instead of printing all the jobs.
The <h2> element wraps the job title. You can use the ‘string’ argument to filter specific data.
python_jobs = results.find_all('h2', string='Python Developer')
The above code searches for the string which matches Python Developer in all the <h2> elements. You can call the find_all method directly on the results variable. Now print the python_jobs variable to your console and check the output. It returns an empty list.
[]
There is a Python developer job in the results. But it’s not getting filtered properly because we are using equal to ‘=’ operator which checks for the exact string. Lower or Upper case of the job posting prevents it from matching with the string. We need to find a generalized way to search the string.
Pass a Function to a Beautiful Soup Method
We can pass not only the string argument but also pass functions as an argument to the beautiful soup object. To get the python developer jobs, change the code a bit.
python_jobs = results.find_all('h2', string=lambda text: 'python' in text.lower())What the lambda function does is, it converts the text of every <h2> element to lower case and checks if the substring ‘python’ is present in the text. We found a job posting now:
Python Developer Atash Enterprises, LLC Columbus, OH
In case you don’t find a match, don’t worry. Because the job advertisement on the webpage keeps changing frequently. Using text content the process of finding the relevant information on a webpage is powerful. Using beautiful soup you can accomplish this by checking for either exact string or passing a function as an argument to filter out the text.
Extract Attributes From HTML Elements
Now we have filtered the relevant jobs, the company, and the location of the jobs. The only thing missing here is we have to apply for the job.
You might have noticed while inspecting the page, the element which has the HTML class ‘title’ contains the link. The .text returns only the text content and misses out the link. To get the URL, we have to extract the attribute.
Check the output of the python_jobs variable. The URL is present in the href attribute of <a> tag. We have the fetch the <a> element. Then using square bracket retrieve the value of the href attribute.
python_jobs = results.find_all('h2', string=lambda text: 'python' in text.lower())
for job in python_jobs:
link = job.find('a')['href']
print(job.text.strip())
print(f"Apply here: {link}\n")The output displays the link to the filtered python developer jobs.
Conclusion
In this tutorial, you have learned on Python Web Scraping using Beautiful Soup. We have covered the following points
- How to inspect the webpage in the browser using Developer Tools.
- How to make use of encoded information in the URL.
- Using Python’s requests library how to download the HTML content of a webpage.
- Using beautiful soup how to parse the HTML data and retrieve only the relevant information.
- What points need to consider before scraping a webpage, whether it is static, hidden, or dynamic.
There are other job boards which return the static HTML responses, you can practice by visiting those sites.